A Mechanistic View of Thinking and the Brain
by Janaki Ram Puli
I have been thinking about learning, the brain, and how all of this relates to LLMs. I have also noticed significant changes in the way I read, learn, and focus. These changes are driven by AI-generated content, short-form media, and rapid context switching. So I want to explore what is actually going on inside the brain and how it relates to LLM thinking.
Contents
- Content/Code generation is cheap, verification is still hard
- Attention span
- Two Modes of Thinking
- Chunking
- Neurotransmitters and what motivates us?
- Procrastination as a habit loop
- Techniques that help
- Flow state
- Thinking… VS
<thinking>...</thinking> - Fast thinking and slow thinking
- The illusion of thinking
- What we do differently?
- References
Content/Code generation is cheap, verification is still hard
There is a shift in how people code or even write content, and a lot of it is AI-generated at this point: articles, emails, messages, PRs, etc. Having used them quite extensively, I can usually tell immediately. There is nothing wrong with that. In fact, they do a much better job than me in any of these areas. But it’s also very hard to verify whether anything in it is actually correct. Generation has become extremely cheap. Verification is still expensive. As the volume of generated content grows, it gets more expensive.
Attention span
With short-form content everywhere and LLMs helping with everything, I’ve noticed that my attention span has gone down significantly. I can do things faster now. But I’m also trying to do everything faster, even when that’s not the right way to approach the problem.
For example:
- research
- learning a new topic
- deeply understanding a concept
Those things require long periods of uninterrupted thinking. But that’s getting harder. How information is engineered, curated, and served to us matters. Short-form video and infinite scroll are designed with no natural stopping cues. Constant rapid context switching is affecting cognitive performance and memory. Rapid switching between contexts increases cognitive load and reduces attention and learning efficiency.
Coding itself is becoming somewhat commoditized. I honestly don’t remember the last time I manually wrote large chunks of code at work.
But long-term skills like deep thinking and genuine understanding feel more valuable than ever. This can be a valuable skill to possess in the era of vibe-coding.
So I thought it’s better to take a step back and understand what is actually going on.
So I started exploring:
- how humans actually learn
- how the brain processes ideas
- how thinking works
- how this compares to LLMs
- what the gaps are between our brain and LLMs
While exploring, I came across this blog post from Aleksa Gordić’s blog [2] 5 Tips to Boost Your Learning - Aleksa Gordić. .
And the Coursera course Learning How to Learn [3] Coursera: Learning How to Learn. .
Two Modes of Thinking
The brain operates in 2 modes of thinking.
Focused mode - focused thinking happens when we’re actively concentrating on something. This requires deliberate attention and pattern matching to already existing networks.
- solving a math problem
- reading something carefully
- reasoning, deliberate attention
Diffuse mode - this mode of thinking happens when we’re relaxed.
- walking
- showering
- sleeping
- daydreaming
During this mode, the brain actually makes connections between ideas that may not seem related before. Quite often, a good idea strikes us during this mode (light sleep, shower, brisk walk, …): the “aha” moment.
Can these 2 run simultaneously? No.
Chunking
A chunk in the brain is basically a piece of knowledge. It can be a pattern, concept, or a skill … When you truly understand something, it becomes a chunk.
To form a chunk, you need:
- focused attention
- practice (DIY)
- rest (diffuse mode to consolidate)
- recall (retrieve it later to reinforce)
- make mistakes (error signals to correct)
Illusion of competence: simply looking at or reading through solutions, or watching some YouTube stuff to understand something, can create an illusion of competence.
It happens, right? You think you understand that topic until someone asks about it, or something goes wrong, and you realize that you didn’t understand it properly. So you have to work on it yourself to build the neural pattern.
A useful technique before actually learning any topic is to get a sense of the big picture: skim through headings, images, tables, and the author’s work. Also, I don’t want to overlearn something; that can have diminishing returns. Better to jump to something else.
Neurotransmitters and what motivates us?
- Acetylcholine - associated with focused learning and attention
- Dopamine - encodes reward anticipation and assigns value to stimuli. It spikes in anticipation of a future reward. This is required to bridge the gap between the current state and the desired goal.
- Serotonin - linked to social behaviour and risk-taking. Lower serotonin correlates with more risk-averse, emotionally reactive behaviour.
- Emotions broadly - being angry, stressed, or afraid actively impairs learning.
How is the brain deciding that this is beneficial? Before any significant task, the brain performs a quick cost-benefit analysis:
- effort required now
- reward that may come later
The issue is that the brain heavily discounts future rewards - temporal discounting. So difficult tasks feel painful now because the benefit feels distant and abstract.
Meanwhile, scrolling provides immediate reward with near-zero effort.
All the modern social media systems are very good at exploiting this. Short-form videos and infinite scroll constantly reset our attention. Now our brain, having seen all this, expects new information every 15-30 seconds. Once your baseline dopamine level is elevated through this overstimulation, the threshold for new information to feel stimulating rises. If something takes longer to understand, it suddenly feels boring and slow.
But the brain is plastic, and we can rewire it based on this experience.
Procrastination as a habit loop
This is the loop that is actually causing procrastination (habit loop).
- cue - a trigger (time, location, emotion, …)
- routine - the action
- reward - immediate relief
- belief - reinforcement
The loop becomes so automatic that you can close an app and reopen it five seconds later without consciously deciding to.
example: cue -> difficult task (as perceived by the brain) routine -> scroll Twitter reward -> immediate relief belief -> the brain quickly learns that avoiding a task produces the dopamine reward
You need to change your reaction to the cue. Rewire the routine by substituting a different behaviour.
Techniques that help
Pomodoro Technique
- 25 mins focused work
- 5 minute break
- repeat
Why will this help? We’re trying to focus on the process rather than the result. I need to finish this paper -> I’ll work on this for 25 mins. Psychological resistance is lowered as part of this.
Spaced Repetition
Instead of doing everything at once, try to revisit ideas over time, like working on some idea/project/paper.
Why does this work? It gives the brain time to consolidate and recall. STM -> consolidation -> LTM.
Temptation Bundling
Pair a high-effort task with an enjoyable activity. The dopamine from the enjoyable activity lowers the perceived cost of doing the hard task.
Physical Exercise
Physical exercise promotes the growth of new neurons and significantly improves mood, focus, and memory consolidation. Even a brisk walk can surface insights that were stuck during focused work.
Writing
One thing I personally noticed:
When I write about something and take notes, I feel much more in control of it (sometimes it’s an illusion and often it’s real). It forces you to organise and articulate what you know, which reveals the gaps.
As the saying goes - if you can’t explain it, you don’t understand it.
Flow state
I cannot describe what a flow state is, but you know when you’re in it. When I enter it, I can focus for extremely long periods of time without any distraction.
Some patterns I have noticed:
- working on something genuinely driven by curiosity
- having a clear goal and visible progress
Thinking… VS <thinking>...</thinking>
It’s natural to compare human cognition with modern LLMs. Do they actually think?
First, they’re impressive and probably the coolest tech we have. And at the same time, they’re quite dumb in that they can’t solve simple problems sometimes and struggle with context rot, instruction following, …
So what makes them similar to us, and what makes them different from us?
First, they’re autoregressive in nature -> they generate the next token based on the probability distribution over all previous tokens.
\[P(\text{next token} \mid \text{previous tokens})\]Now we have a really powerful pattern predictor.
What do humans seem to do differently?
- we have persistent memory
- world models
- embodied experience
- planning abilities
- memory consolidation
- diffuse thinking
- continual learning
We can spend hours or even days thinking about a problem before actually responding.
Fast thinking and slow thinking
Fast thinking - operates quickly, is intuitive and automatic, and requires little energy. Slow thinking - deliberate, logical, and expensive. For LLMs: Fast thinking - standard next-token generation with no reasoning. Slow thinking - Chain-of-thought (CoT) prompting, reasoning step by step.
Methods like CoT (chain-of-thought) prompting ask models to reason step by step.
<thinking> step1 step2 step3 ... </thinking>
Ex. Let’s think step by step.
This made a huge difference for thinking/reasoning models compared to normal models.

But are they really thinking? Or is this just an illusion, where it is generating a sequence of tokens that look like reasoning?
The illusion of thinking
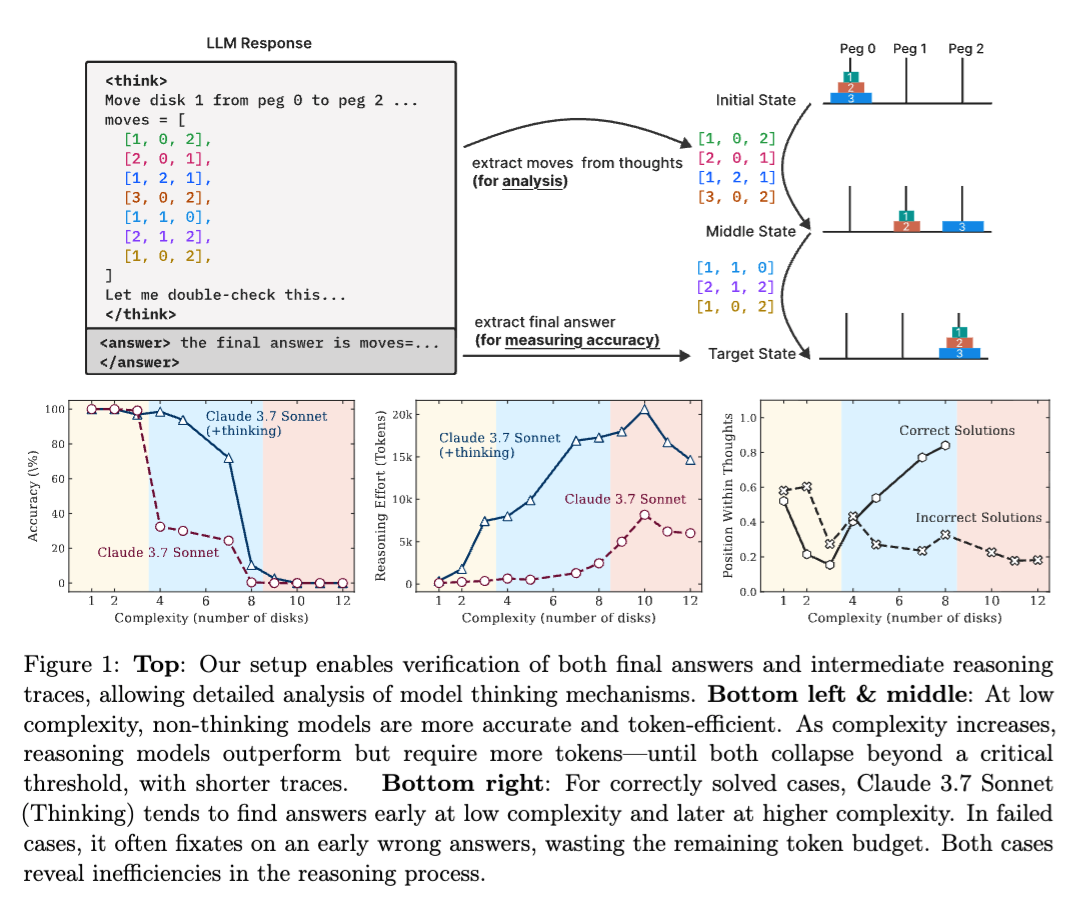
The “illusion of thinking” paper [4] The paper discussing the ‘illusion of thinking’ in reasoning models. suggests that reasoning models perform well on medium-complexity tasks but struggle with complex reasoning that requires novel problem solving.
Is the <thinking> block generating a sequence of tokens that looks like reasoning, in the same way I can write “let me work through this” and then actually reproduce a memorised solution?
And LLMs compound errors as they generate longer sequences. Without a persistent world model or genuine planning mechanism, errors in early reasoning steps propagate and amplify. Common-sense physics, causal reasoning, and anything requiring grounding in sensory reality remain difficult.
What we do differently?
What labs are doing right now:
- Token-level next-word prediction
- Post-training and alignment
- Scaling - more data, more compute, more parameters
What would it take for AGI?
-
World models
We have some internal models for physical reality. Ex. I can predict where a ball might land when I throw it. Internal representations that allow agents to simulate, predict, and plan.
-
Continual learning
We keep learning continuously, and we don’t overwrite older memories. So, the ability to integrate new knowledge without forgetting much.
-
Latent space reasoning
Thinking in compressed, abstract representations rather than just at the token level. Latent variable z and the final outcome variable y.
$P(y) = \sum_{z \sim P(z)} P(y \mid z)$
let x denote the question, y the answer to it, and z as the latent
$P(y \mid x) = \sum_{z \sim P(z \mid x)} P(y \mid x, z)$
-
Diffuse thinking
We can solve problems when we’re not actively thinking about them, like a background process. Instead of step by step, the reasoning emerges gradually by de-noising latent representations. Chain of thought -> diffusion of thought
-
Embodied intelligence
We can interact with the physical world and learn from it. vision, touch, physics, motion, …
-
RL environments
RL in rich, uncertain environments seems like a natural step for developing planning and adaptive behaviour
-
Memory consolidation
We constantly re-organize our memory. Agents should constantly consolidate, reconsolidate, and selectively retrieve knowledge over long time horizons.
The first principle is that you must not fool yourself - and you are the easiest person to fool.
Some ideas that I want to explore more deeply in future:
- thinking in latent space
- world models
- diffusion models
- continual learning
- reward hacking during RL
- how to perform RL in CoT style